Big question
Current leveldb implementation uses uniform setting for all Bloom filters for hot and cold SSTable, which is not efficient to reduce unnecessary I/O.
Background
In leveldb, in order to reduce unnecessary I/O for non-exist data, bloom filter about SSTables are cached in the memory. When user search for a key, the key is first checked in related bloom filter. Then if bloom filter returns true, that SSTable is fetched from disk (one I/O) and leveldb uses binary search to locate that key.
Since bloom filter has a parameter, called false positive rate (FPR). It may tell a lie when the key is not exist in SSTable. This will cause unnecessary I/O. In order to reduce those I/O, we must reduce FPR and use more memory.
$$ P = \left( 1 - e ^ { - k n / m } \right) ^ { k } $$
- k: number of function
- n: number of inserted key
- m: number of bit
Assuming we uses 10 bit per key, and the function number k is 3, then the FPR will be 1.74%.
Specific questions
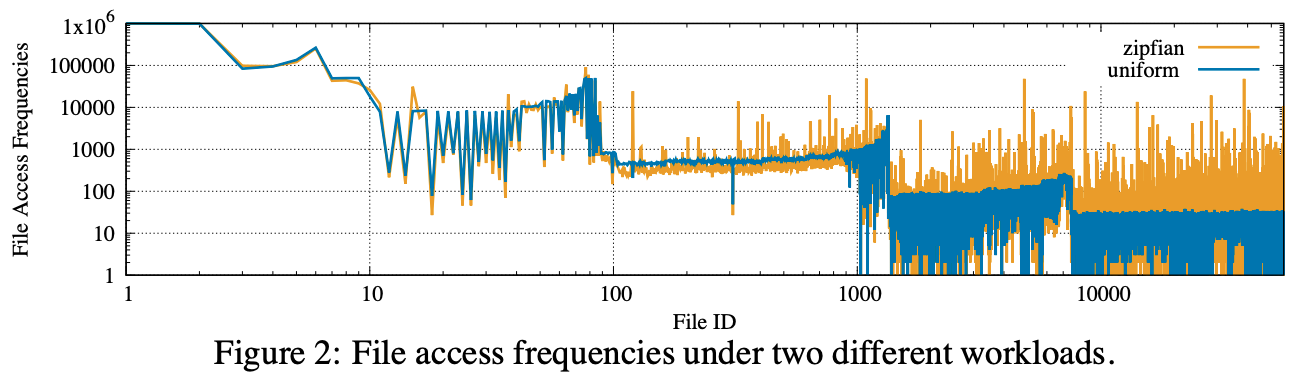
Because SSTable access pattern is not uniform. Using uniform size of bloom filter is not efficient. The basic idea is allocate more memory to hot data and less memory to cold data.
Solution
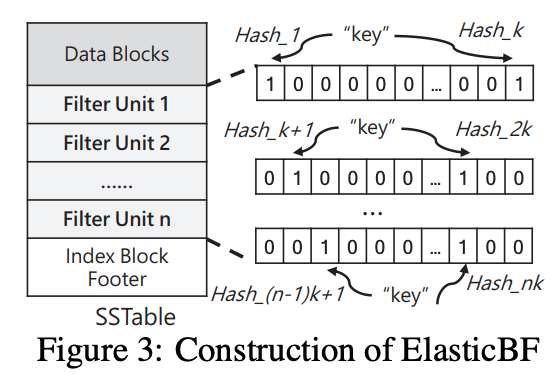
The solution is building multiple filters when constructing each SSTable, and each filter is usually allocated with smaller memory size, which is called filter unit. Hot SSTable will cache more filter unit in memory.
A cost function
$$ E [Extra IO ] = \sum _ { i = 1 } ^ { n } f _ { i } \cdot f p _ { i } $$
- n: number of SSTable
- fi: access frequency of SSTable i
- fpi: false positive rate of SSTable i
ElasticBF adjusts the number of filter units for each SSTable only when the metric E[Extra IO] could be reduced under the fixed memory usage.
Multi Queue design
The adjustment of Bloom filter proceeds as follows. Each time when a SSTable is accessed, we first increase its access frequency by one and update E[Extra IO], then we check whether E[Extra IO] could be decreased if enabling one more filter unit for this SSTable and disabling some filter units in other SSTables so as to guarantee the same memory usage. However, one critical issue is how to quickly find which filters should be disabled but not incurring a large overhead
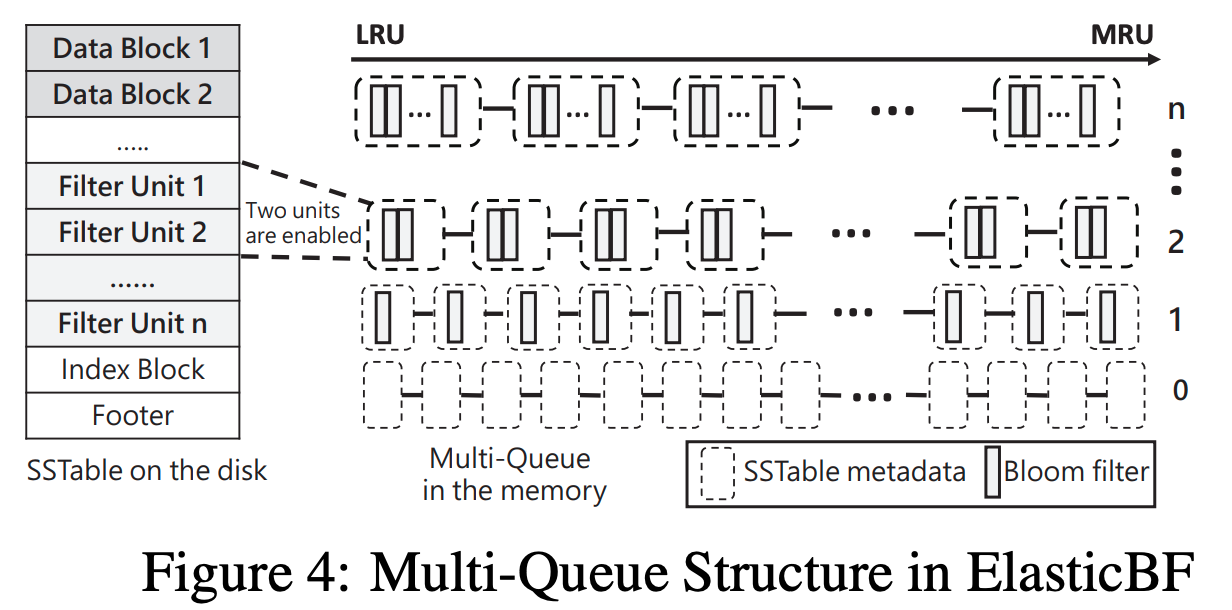
This paper maintained a LRU queue. Each element of a queue corresponds to one SSTable and keeps the metadata of the SSTable, including the enabled filter units residing in memory. Qi manages the SSTables which already enabled exactly i filter units, e.g., each SSTable in Q2 enabled two filter units.
Each metadata will have a currentTime + lifeTime counter as expiredTime.
- currentTime: number of total Get requests
- lifeTime: when will this SSTable expire, the life interval
A read will cause the metadata been updated (update currentTime).
I guess those multi level queue is priority queue, sorted by the the expireTime. Then this means every access will first locate the metadata, then reorder the queue.
How to located the metadata, brute force? How about the reorder overhead?
My comments
This Elastic idea is not the first I head. In SIGMOD17, a paper: Monkey, discussed how to use different size of bloom filter for SSTable in different level in LevelDB. Their idea is allocate more memory to higher lever SSTable and less memory to lower level SSTable.