Big question
Cloud databases should support dynamic allocation of hot and cold data to fast and slow device. So the client can get the best performance within their budget.
The author introduced a system that support dynamic allocation of storage system based on LSM-tree.
Background
Locality in SSTable
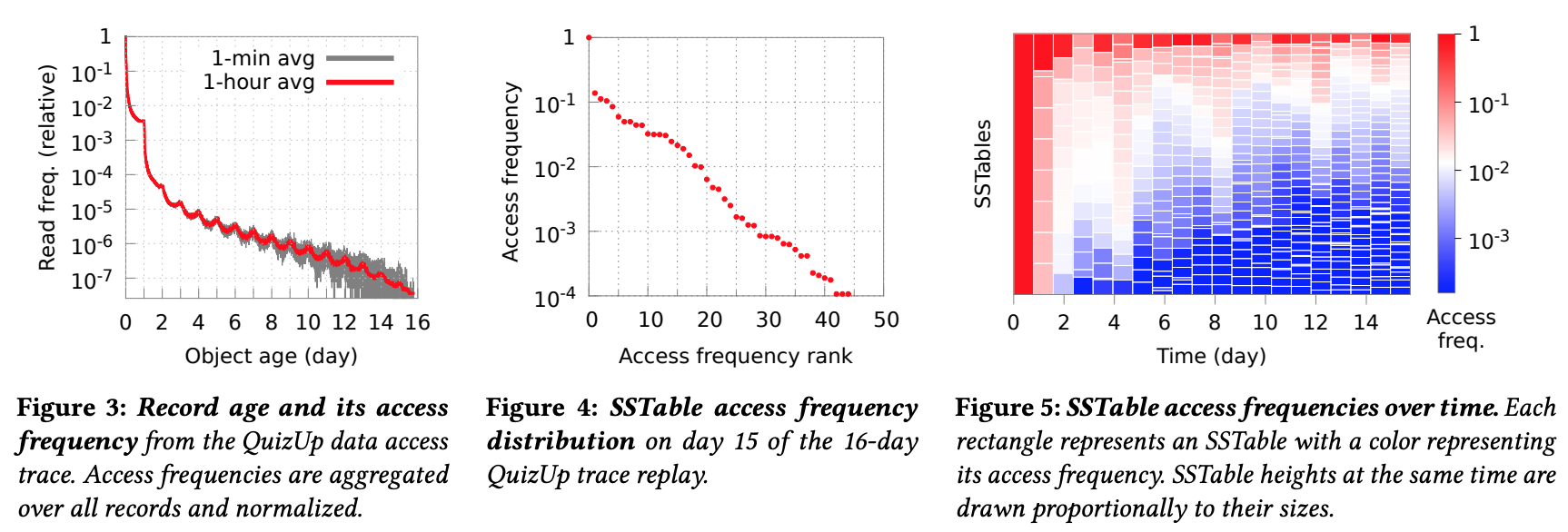
There are some locality in SSTable access. (This paper uses QuizUp workload to do the analysis)
Figure 3indicates that younger data will have more access while older data have less access.Figure 4illustrates that the hottest data can be 4 orders of magnitudes than the coldest data.Figure 5says that As more records are inserted over time, the number of infrequently accessed SSTables (“cold” SSTables) increases, while the number of frequently accessed SSTables (“hot” SSTables) stays about the same.
Locality in SSTable components
Components consist of metadata(including bloomfilter, record index) and data records.
Specific questions
Get the optimal SSTable to be stored in fast storage
With those pattern, this paper try to solve this specific question:
Find a subset of SSTables to be stored in the fast storage (optimization goal) such that the sum of fast storage SSTable accesses is maximized, (constraint) while bounding the volume of SSTables in fast storage.
They use this model to do some optimization.
$$
P _ { f } S _ { f } + P _ { s } S _ { s } \leq C _ { \max }
$$
$$
S _ { f } + S _ { s } = S
$$
- Pf, Ps: unit price for fast and slow device
- Sf, Ss: sum of all SSTable sizes in the fast and slow storage
$$
S _ { f } < \frac { C _ { \max } - P _ { s } S } { P _ { f } - P _ { s } } = S _ { f , \max }$$
maximize
$$\sum _ { i \in SSTables} A _ { i } x _ { i }$$
subject to
$$\sum _ { i \in SSTables} S _ { i } x _ { i } \leq S _ { f , max } and x _ { i } \in { 0,1 } $$
- Ai: number of accesses to SSTable i
- Si: the size of SSTable i
- Xi: SSTable in fast storage or not
This becomes a 0/1 knapsack problem. They use a greedy algorithm to solve this problem.
My comment:
Why not just sorting by the frequency, then put as many as SSTable to fast device directly.
Solving spike or dips
They use a counter to record the access frequency, but they can be affected severely by spike or dips. So they implement a filter through exponential average to smooth the frequency counter.
My comment:
This is like a digital signal filer. Transform function.
My thoughts
The thing I don’t understand is that why memory caching is not enough for those hot data. Maybe one possible explanation is that even hot data is too big to be stored in memory.