Basic
- NoSQL 数据库
- compass app: 连接 mongodb atlas 的官方 app
- mongod: mongoDB 的 database application
- mongo: 提供和 database 进行交互的 shell 接口 application
- 向 mongodb atlas 上传数据
1
mongoimport --type csv --headerline --db mflix --collection movies_initial --host "cluster0-shard-00-00-1cvum.mongodb.net:27017,cluster0-shard-00-01-1cvum.mongodb.net:27017,cluster0-shard-00-02-1cvum.mongodb.net:27017" --authenticationDatabase admin --ssl --username hansonzhao007 --password XXXXXX --file movies_initial.csv
Aggregation Framework
pipeline
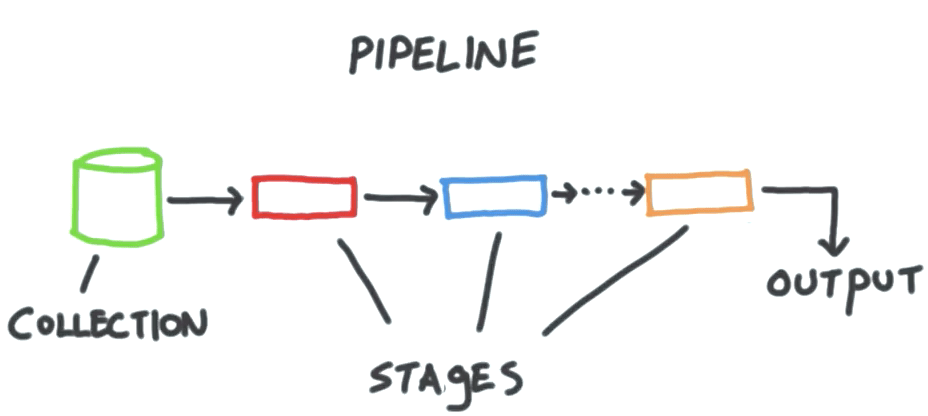
从 collection 里面获得数据,并输入到后面的 stages,每个都进行不同的操作。这些输入输出都是 documents。
stages
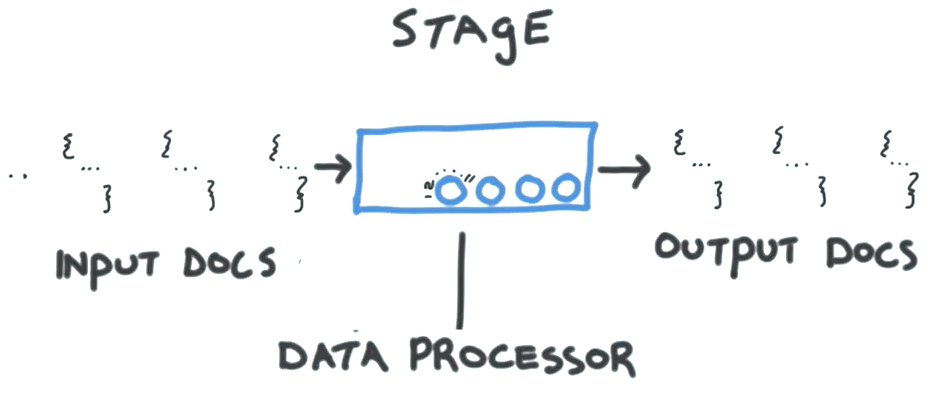
stage 里面可以定义自己对 document 的操作。可以是 reshape,accumulation 等等。
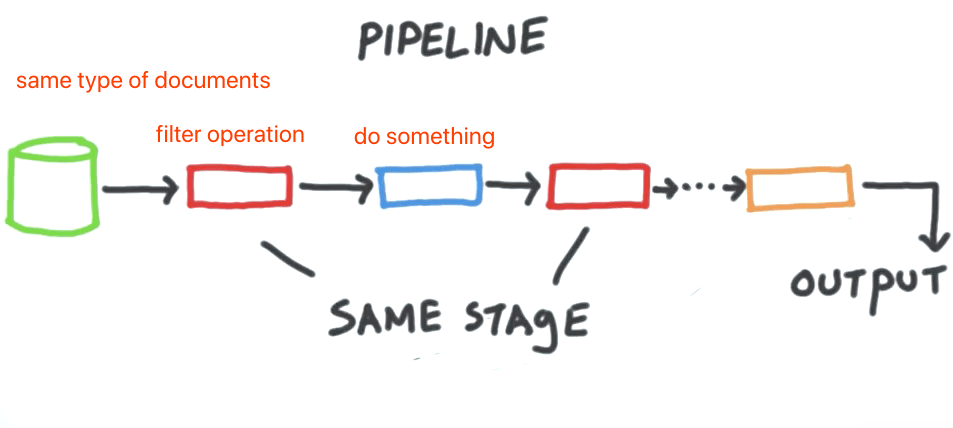
这里的 stage1 可以用来过滤输入数据,不用对每个数据都处理。stage2 可以用来自定义一些数据操作;stage3 可以再次过滤一下。
write a pipeline
下图是python 写 mongodb pipeline 的图例: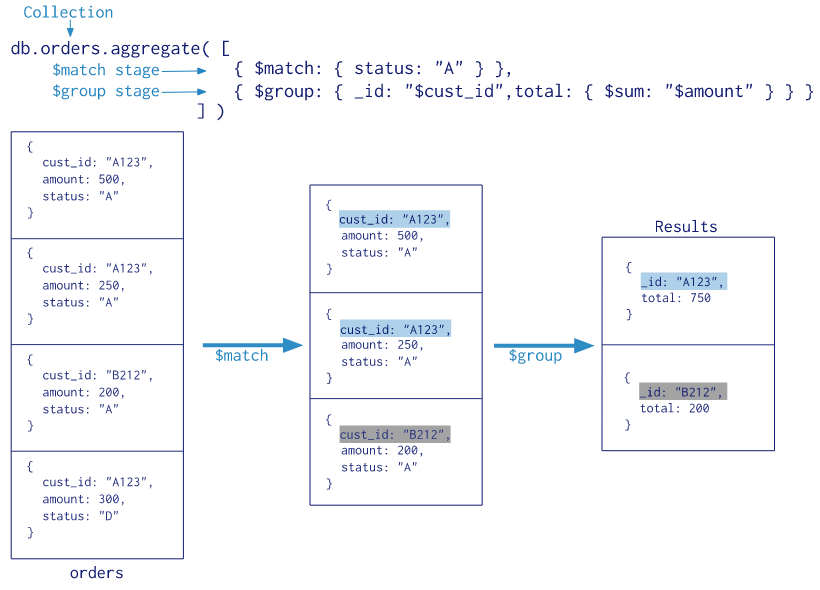
1 | import pymongo |
1 | [{'_id': {'language': 'English'}, 'count': 25325}, |
indexes
加速
使用 index 来加速 mongodb 的查找。
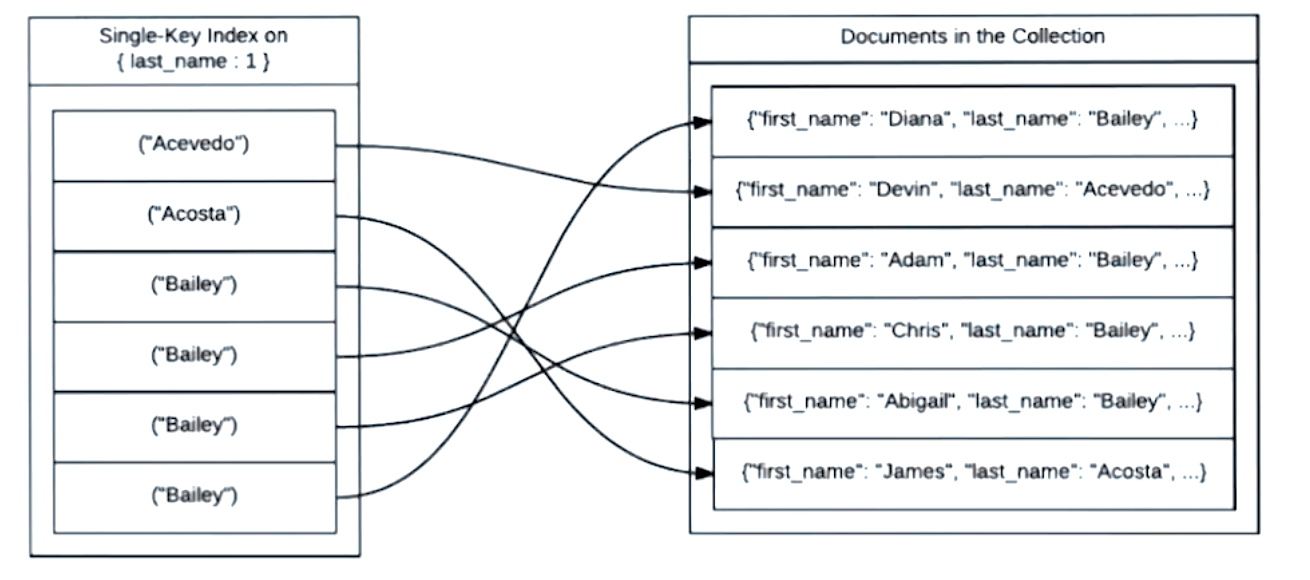
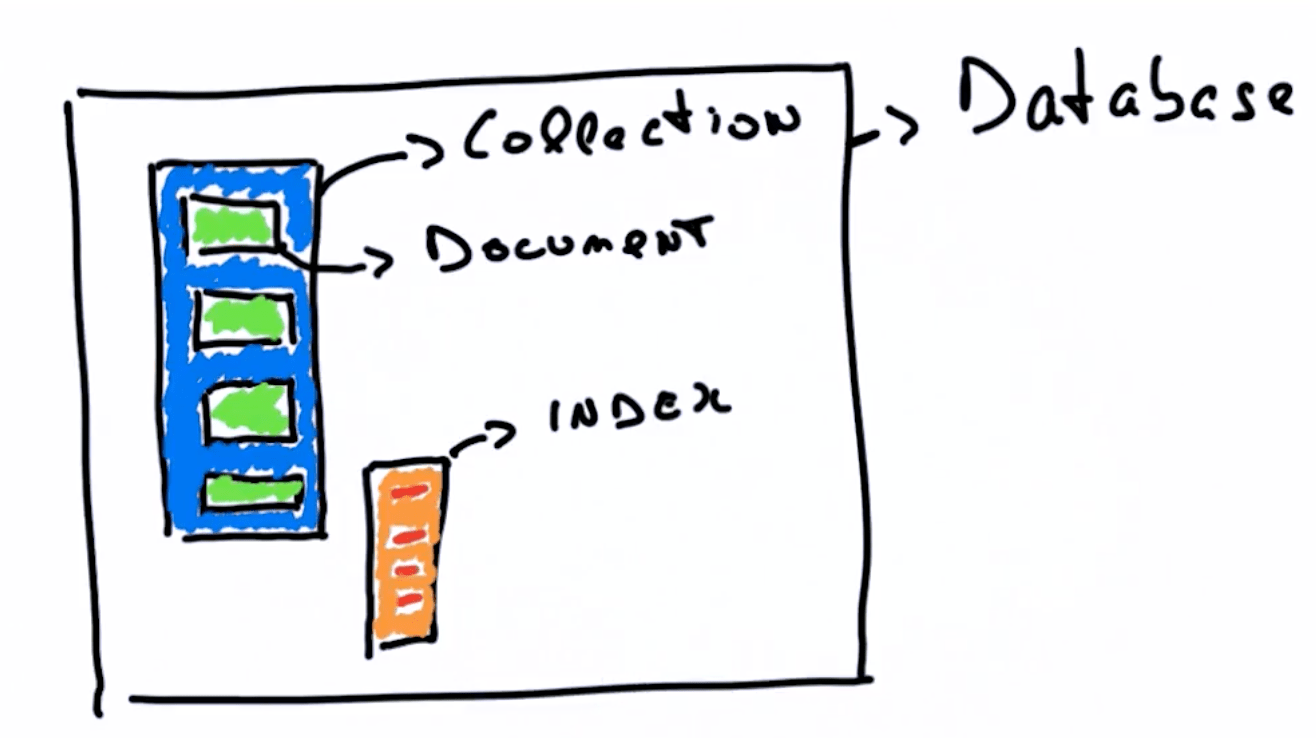
collection 就像是一本书,document 就是书里面的章节内容,而 indexes 的作用就是章节目录。如果没有章节目录,我们想要搜索想要的内容,就只能把书从头找到尾,耗时O(N)。如果有目录,目录按照字母顺序排序,那么想要某一章节,就可以对目录进行 binary search,耗时 O(N),然后直接定位到对应章节。
同时为了满足针对不同 filed 的索引需求,mongodb 的一个 collection 可以有多个 index,用来进行索引。
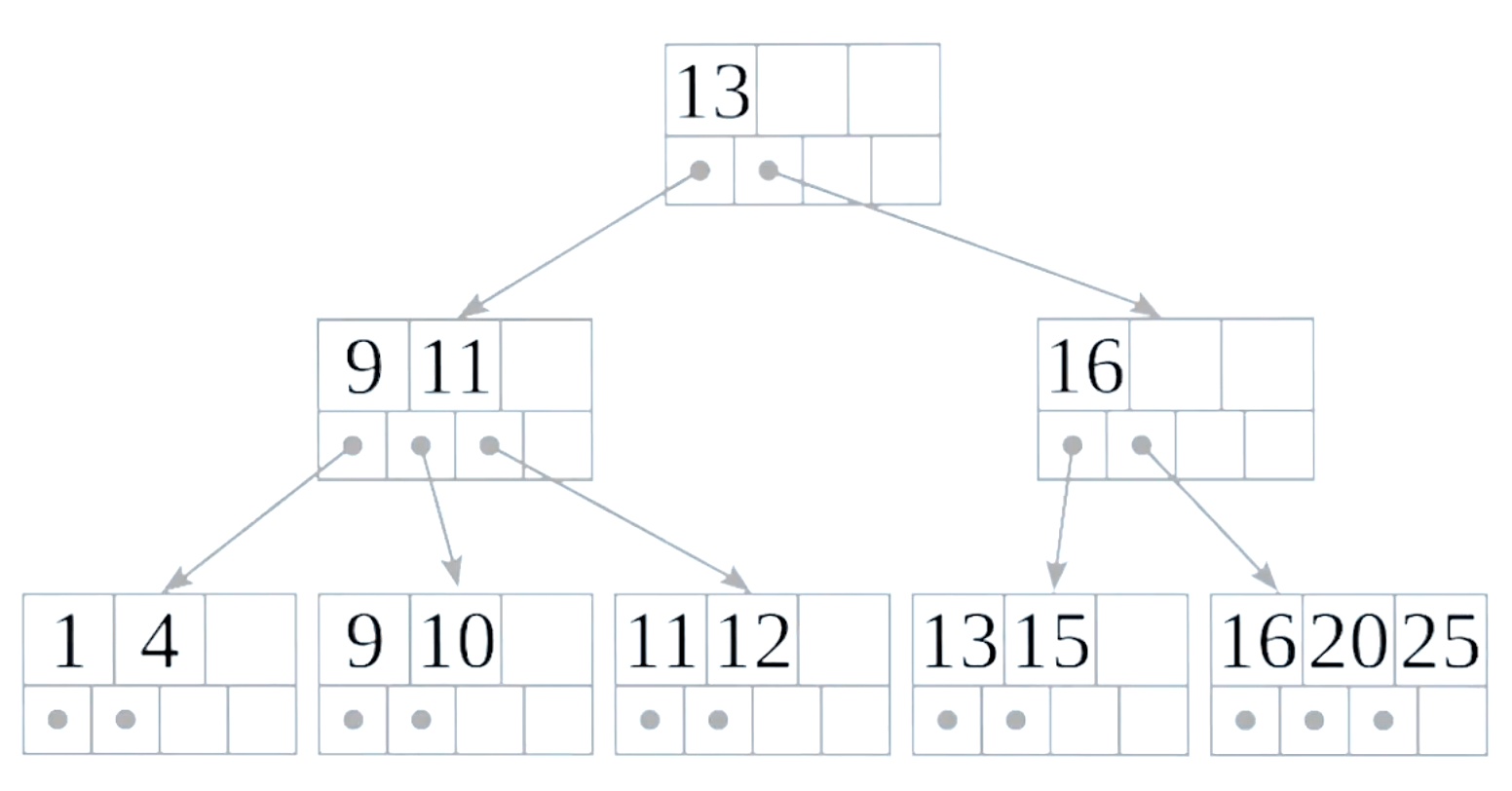
mongodb 使用 B tree 来对 index 进行索引。
下面是使用 index 和不使用 index 进行搜索时,所检测的 document 数量对比。
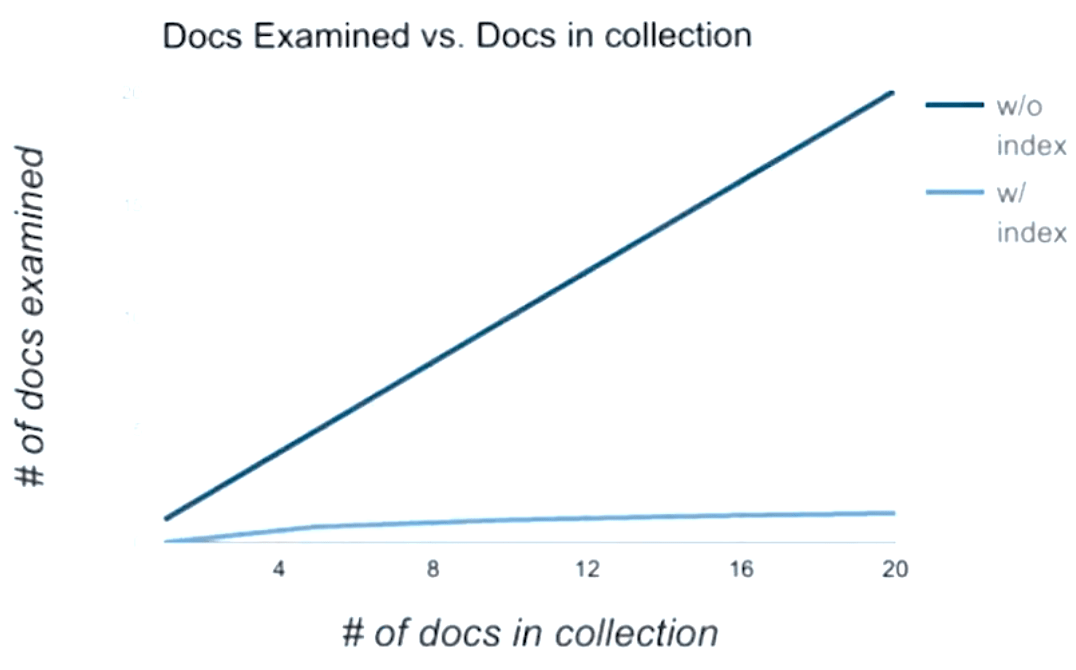
overhead 额外开销
虽然使用 index 对查找进行加速,但是这会对插入引入额外的 overhead(开销),也就是增加了插入数据的时间开销。
这是因为每个 index 的组织结构是 b-tree。在 collection 中插入 document 的时候,会更新 b-tree 的数据,必要时还需要做 rebalance 操作。
组织结构
数据是怎么存储的。
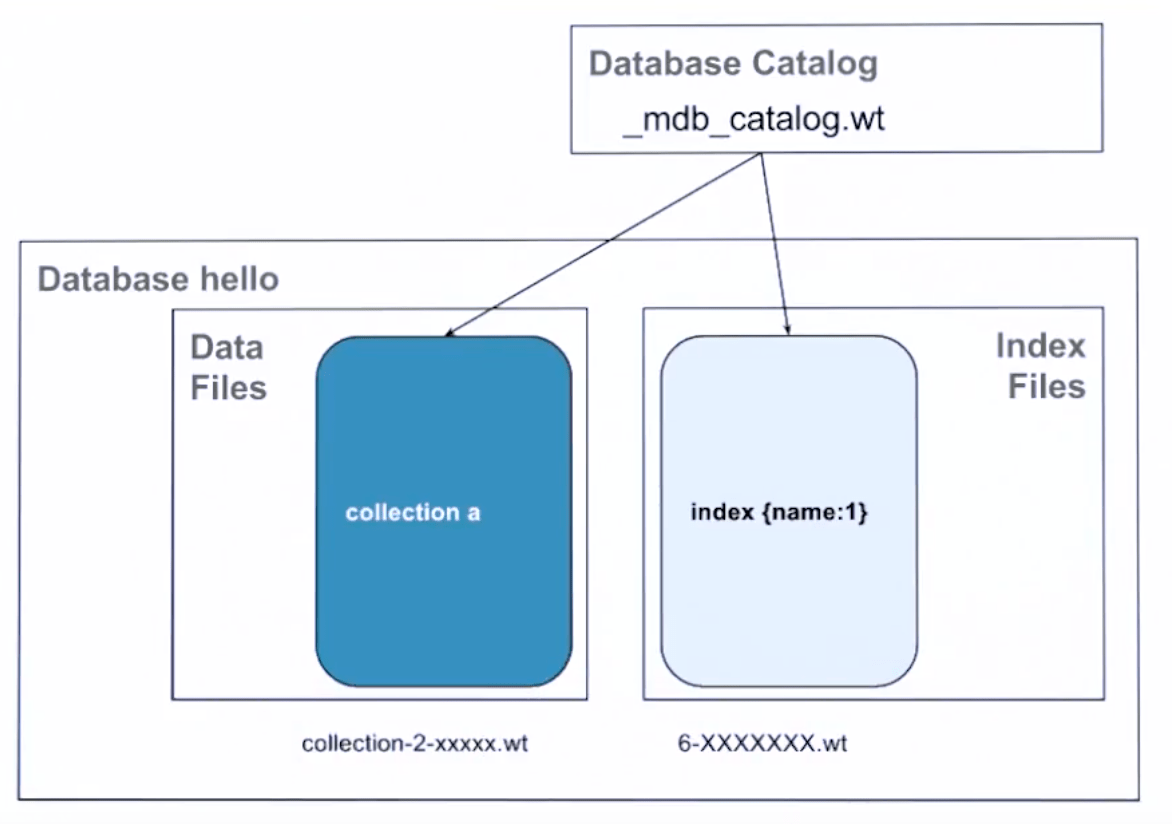
在 mongodb 存储数据库的文件目录下,有这些文件: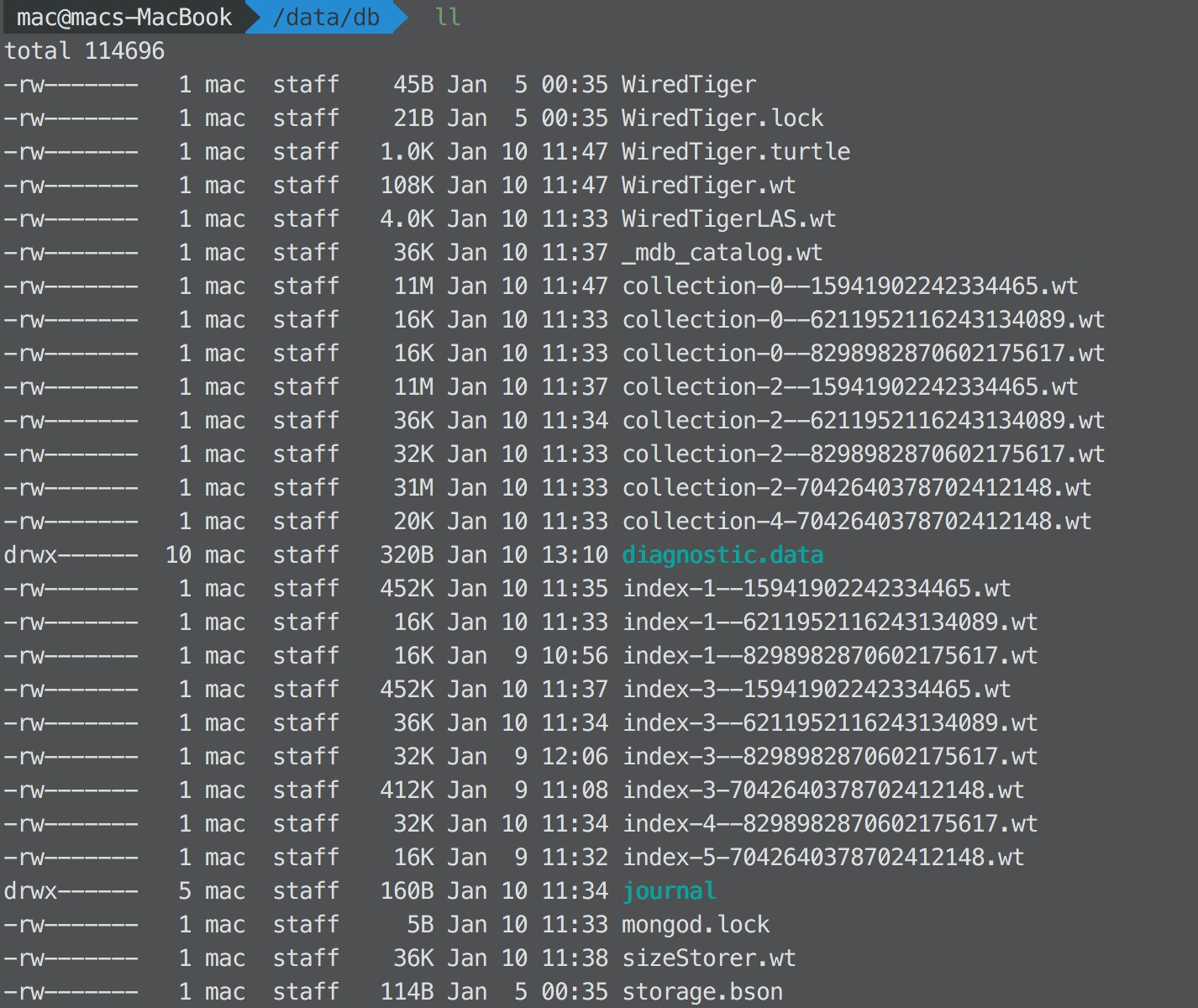
collection-*.wt: 数据库的 collection 文件index-*.wt: 数据库建立的 index 文件
现在的数据库组织形式还是 flat 的,也就是所有数据库文件存储在一个目录下。
我们可以使用 --directoryperdb 命令让 mongodb 将数据库存储时候按照文件夹区分开:
1 | mongod --dbpath --/data/db --fork --logpath /data/db/mongodb.log --directoryperdb |
这样再看目录:
可以看到每个数据库都有自己的文件夹目录了。但是在文件目录里面,比如 local 文件里面,collection 和 index 文件是 flat 的平铺在里面的,并没有区分文件夹。
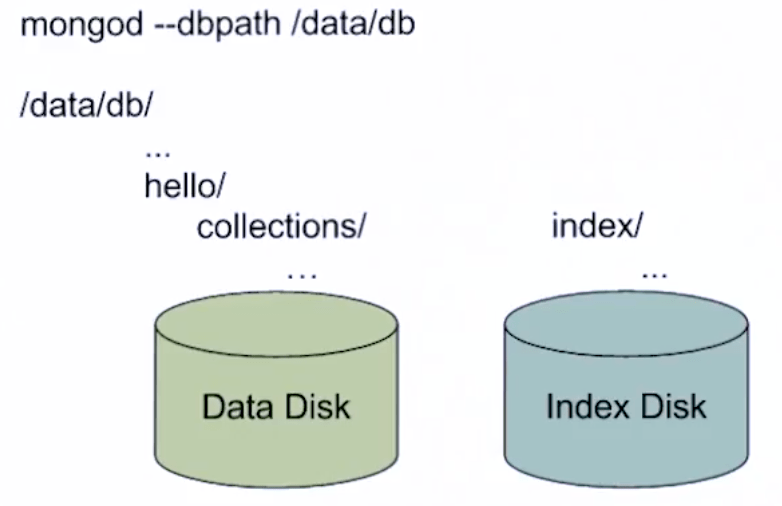
我们还可以使用 --wiredTigerDirectoryForIndexes 命令,在数据库文件夹里,给 collection 和 index 各自也建立文件夹。
1 | mongod --dbpath --/data/db --fork --logpath /data/db/mongodb.log --directoryperdb --wiredTigerDirectoryForIndexes |
这时候再看 local 文件夹里:
已经有了 collection 和 index 两个文件夹了。
之所以这么做,是为了提升数据库的性能。我们可以将 collection 和 index 放在两个不同的 disk 上。这样利用两个 disk 的 parallel 读写(parallel I/O),提升 mongodb 的数据吞吐量。