导入数据
导入一个 collection
after create MongoDB Altas cluster, import movies_initial.csv file to the cluster.
1 | mongoimport --type csv --headerline --db mflix --c movies_initial --host "mflix-shard-00-00-1cvum.mongodb.net:27017,mflix-shard-00-01-1cvum.mongodb.net:27017,mflix-shard-00-02-1cvum.mongodb.net:27017"--authenticationDatabase admin --ssl --username hansonzhao007 --password Zxsh3017568 --file movies_initial.csv |
导入所有 collection
首先从这里 https://s3.amazonaws.com/edu-static.mongodb.com/lessons/coursera/building-an-app/mflix.zip 下载压缩文件并解压。
1 | # 进入mflix文件夹,并安装依赖环境 |
After installing all the dependencies you can import the data required by mflix into your MongoDB Atlas cluster.
To import this data you’ll first need to paste your connection URI (from the Atlas UI) into env.sh (or env.bat on Windows).
After you’ve update env.sh (or env.bat on Windows) with your Atlas connection URI you can run init.sh (or init.bat on Windows) to import all the required data:
On Windows your env.bat should look like this:
导入过程如下:
最终数据如下: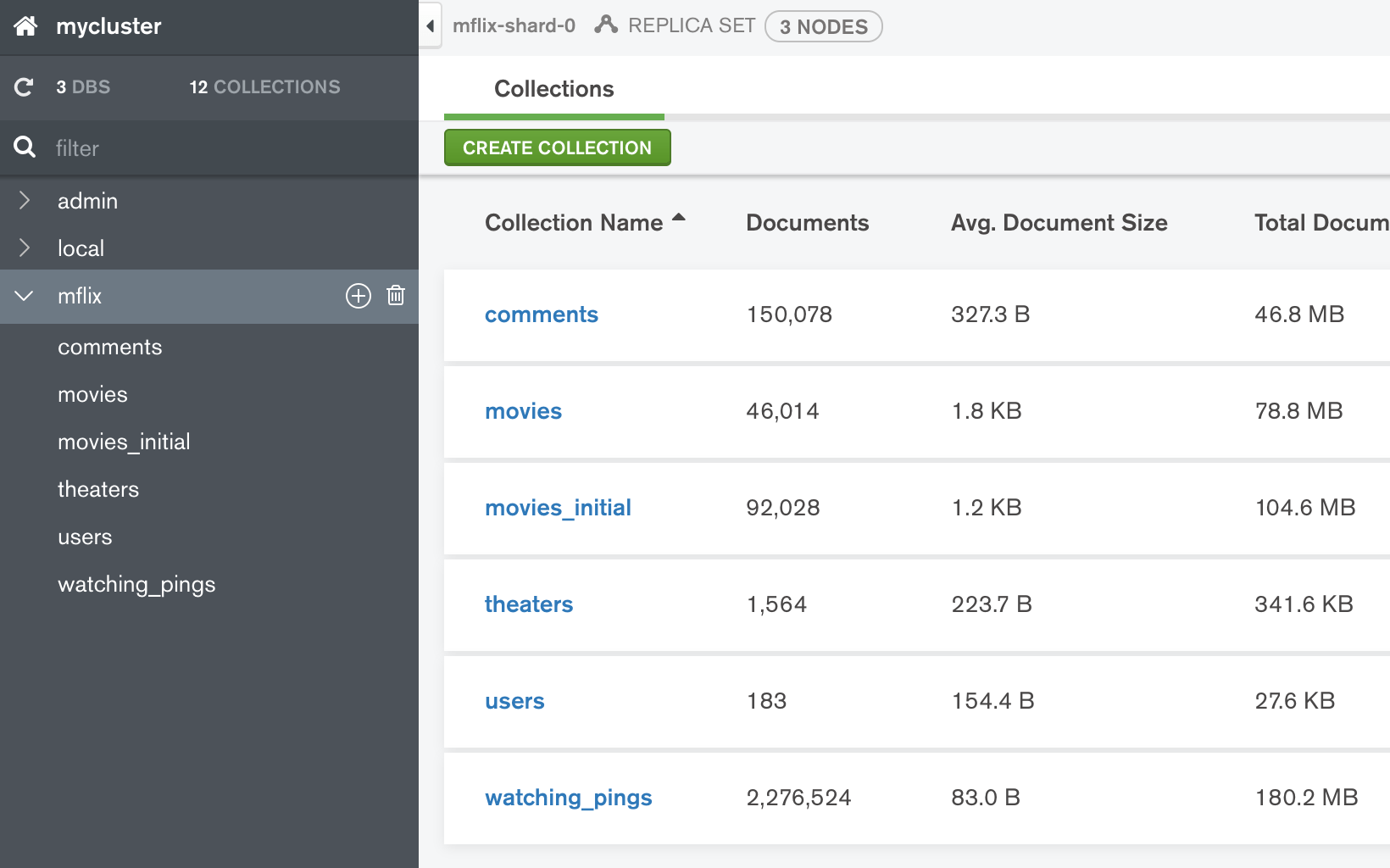
环境配置
除了安装 MongoDB ,要使用 python 来操作 mongoDB,需要使用 PyMongo plugin。安装过程见这里。
链接 MongoDB atlas
因为创建的 atlas cluster 是基于 mongoDB 3.4 的,所以链接的 URI 如下: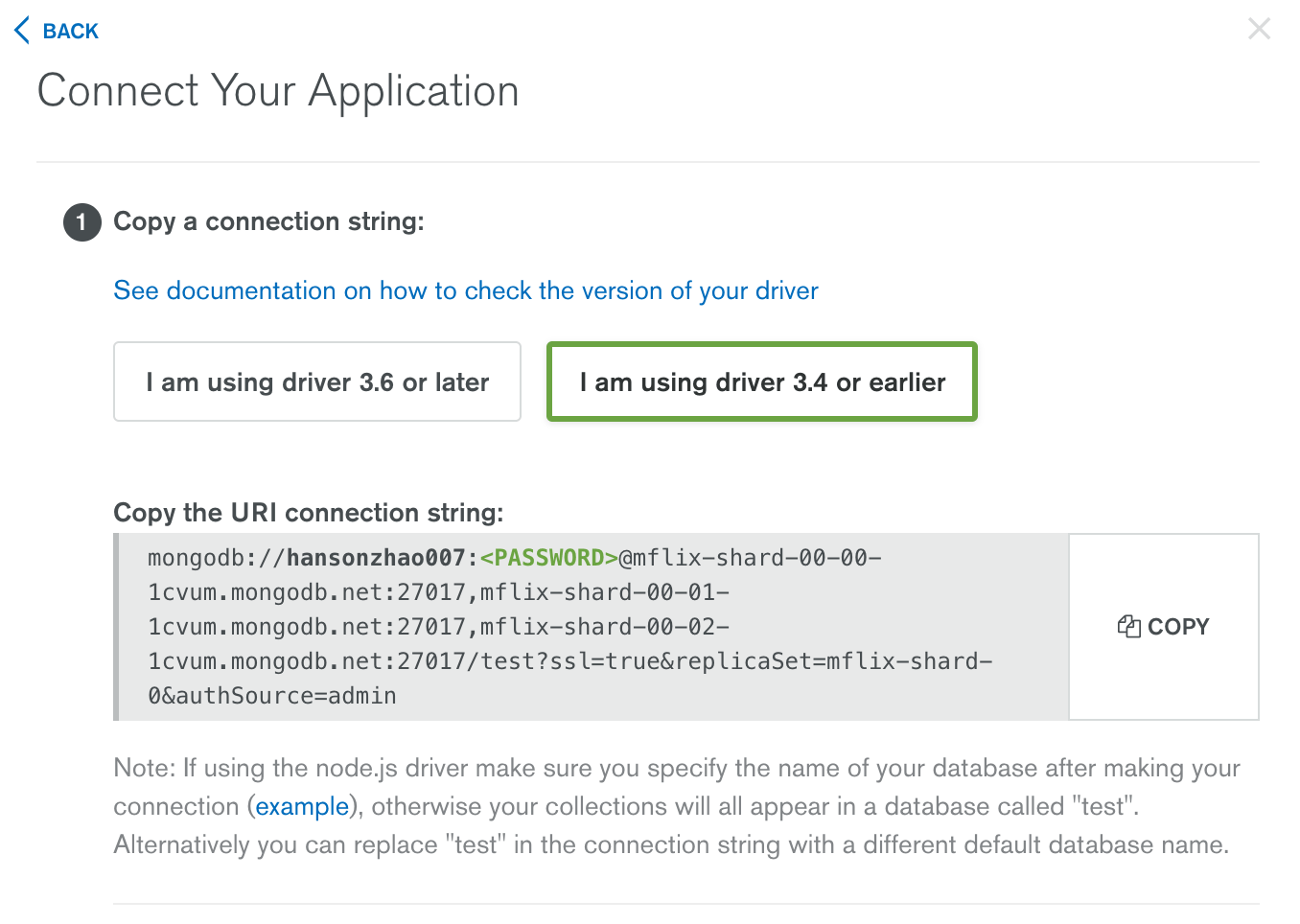
然后使用如下 code 测试链接效果: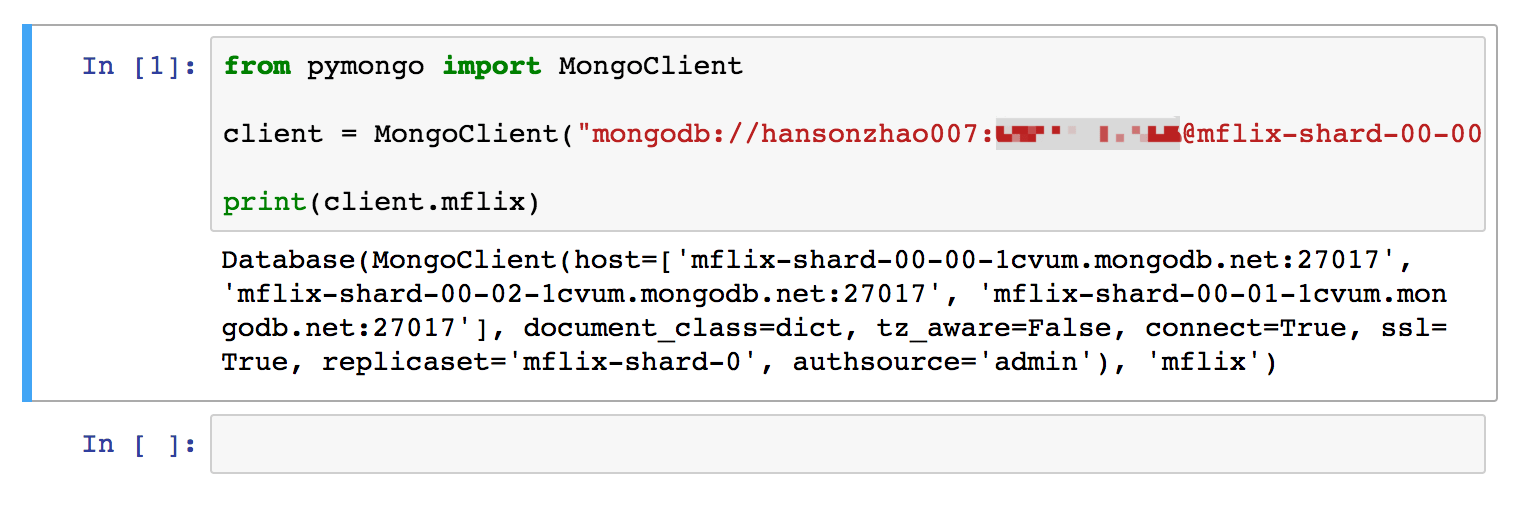
可以看到没有 error 输出,表示链接成功。
MongoDB aggregation
下面测试 mongodb 的 pipeline stage。在连接 mongodb cluster 以后:
1 | import pprint |
Facet
这里facet 的作用是接受上一个 stage 的输入,将当前 stage 拆分成并列的 pipeline,输出多个结果。
1 | pipeline = [ |
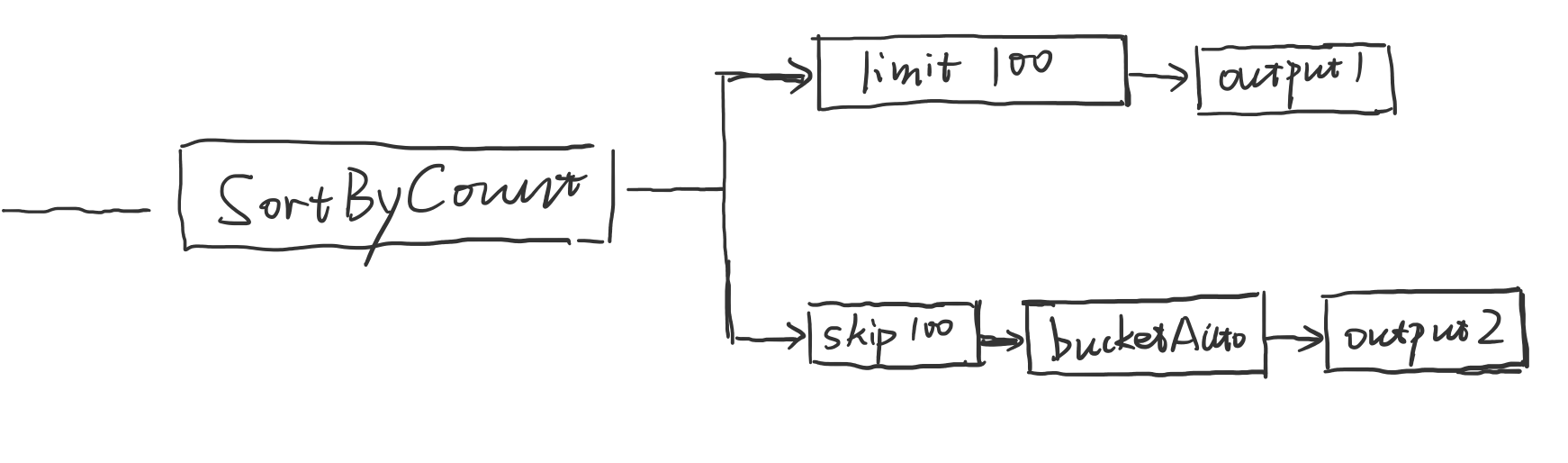
Filter on Scalar Field
1 | filter = {'language':'Korean, English'} |
Geospatial queries
1 | import pymongo |